Plant Biotechnology Journal杂志在线发表了 “Integrating sensor fusion with machine learning for comprehensive assessment of phenotypic traits and drought response in poplar species”论文。该研究工作利用热成像与可见光成像传感器采集多模态数据,从“放大”(包括数据层融合、特征层融合和决策层融合)与“缩小”(数据分解)两个维度系统提取了杨树在干旱胁迫下的多模态表型特征,基于图像处理技术和机器学习算法构建杨树干旱监测模型以对精准监测干旱严重程度及持续时间,进而探索出对杨树干旱胁迫监测最有效的数据处理方式。
全球气候变暖正以前所未有的速度加剧干旱胁迫,对林木生态系统构成致命威胁。作为陆地生态系统最大的碳库,林木一旦受损,可能引发“干旱胁迫-碳排放-气候增温”的恶性循环,导致碳储量急剧下降,生物多样性面临不可逆的丧失。研究警示,气候变化已超越许多物种通过迁移或适应所能承受的极限,直接威胁生态系统的可持续发展,甚至可能诱发全球生态危机。在这一紧迫背景下,传统方法往往依赖单一数据源及处理方式,难以捕捉干旱响应的复杂性,如何突破传统技术瓶颈,融合多源数据的互补优势,探索最优的数据处理方法,构建基于多模态数据的干旱胁迫动态评估体系,精准揭示不同林木品种在干旱中的时空响应差异,已成为破解生态预警困局、抢占全球生态保护战略高地的重要问题。通过综合运用“放大”(涵盖数据层融合、特征层融合和决策层融合)与“缩小”(数据分解)等多种数据处理方法对杨树干旱监测进行了深入研究。系统全面评估了不同数据处理方法在提取表型特征及杨树干旱监测效果中的表现,此外,研究深入剖析了不同数据处理方法生成的新表型特征的应用潜力,为树木健康监测和干旱响应评估提供了坚实的理论基础和实践指导。全文主要研究结果如下:
1.数据分解下提取的表型特征对杨树干旱胁迫的敏感性较低
研究者通过二维小波变换结合灰度共生矩阵算法,对热红外和可见光图像分解为近似系数、水平细节系数、垂直细节系数和对角线细节系数四个子波段,经过灰度共生矩阵从各子波段提取纹理特征,经特征筛选和超参数优化,确定最优特征组合及参数,结合随机森林(Random Forest,RF)、极端梯度提升(Extreme Gradient Boosting,XGBoost)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、决策树(Decision Tree,DT)和类别梯度提升(Categorical Boosting,CatBoost)等五种机器学习算法,构建杨树干旱监测模型。结果显示,当特征数量为24个(热红外图像15个,可见光图像9个)时,模型交叉验证分数最高,表明热红外图像的子波段纹理特征对干旱胁迫响应更敏感(图1a-b)。然而,五种算法的监测表现均不理想,误分类较多,整体精度较低,其中RF和CatBoost表现相对较优(图1c)。总体而言,数据分解提取的纹理特征对杨树干旱胁迫的敏感性不足,限制了监测精度的提升。
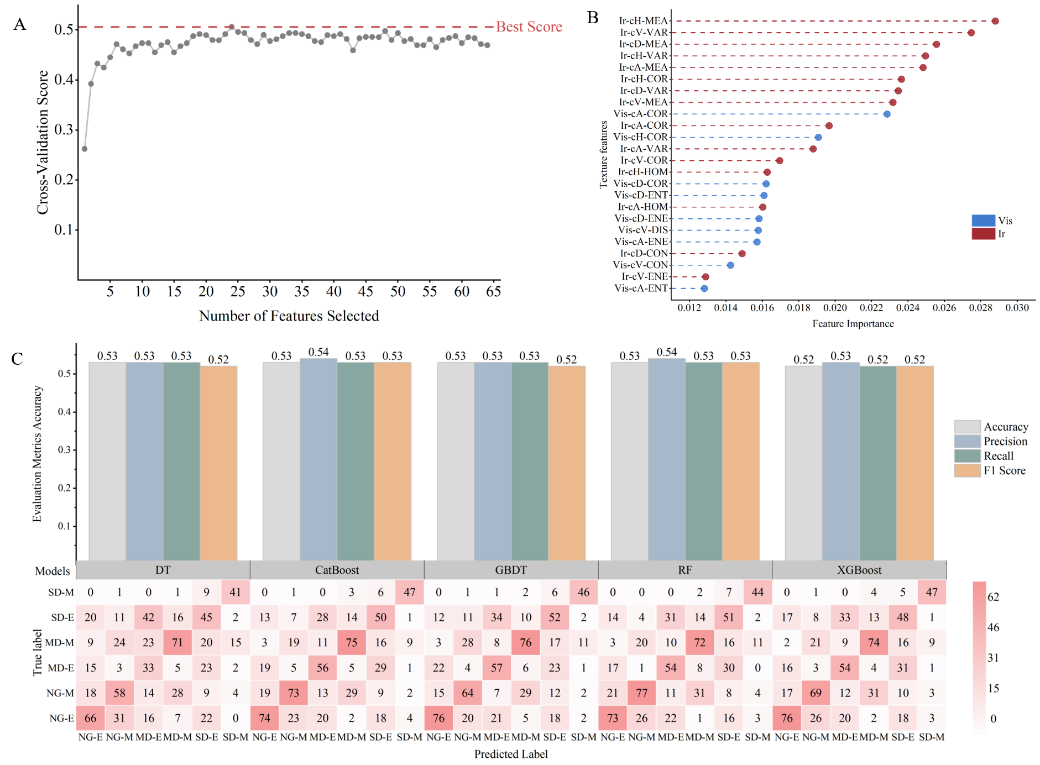 图1 数据分解下特征筛选与机器学习模型结果
图1 数据分解下特征筛选与机器学习模型结果
2.数据层融合中RGB图像融合算法提取的表型特征对杨树干旱监测的精度高于灰度图像融合算法
研究人员比较了灰度图像融合算法(DSFusion(K. Liu et al., 2024)、CrossFuse(Li and Wu, 2024)和DATFuse(W. Tang et al., 2023))和RGB图像融合算法(FISCNet(Zheng et al., 2024)、PSFusion(L. Tang et al., 2023)和SemLA(Xie et al., 2023))在杨树干旱监测中的效果。从灰度融合图像提取纹理信息和灰度通道值,从RGB融合图像提取植被指数和纹理值作为表型特征。通过特征筛选和超参数优化,确定最优特征组合,结合RF、XGBoost、GBDT、DT和CatBoost算法构建监测模型。灰度融合算法中灰度通道值重要性最高,但模型精度较低,DATFuse结合XGBoost表现最佳(图2a)。RGB融合算法性能更优,SemLA提取的特征数量少但对干旱敏感性高,EXG和CIVE权重较大,其结合CatBoost的模型精度最高(图2b)。总体而言,RGB融合算法在监测精度上优于灰度融合,但两者效果均不理想,反映了数据层融合在捕捉干旱特征方面的局限性。
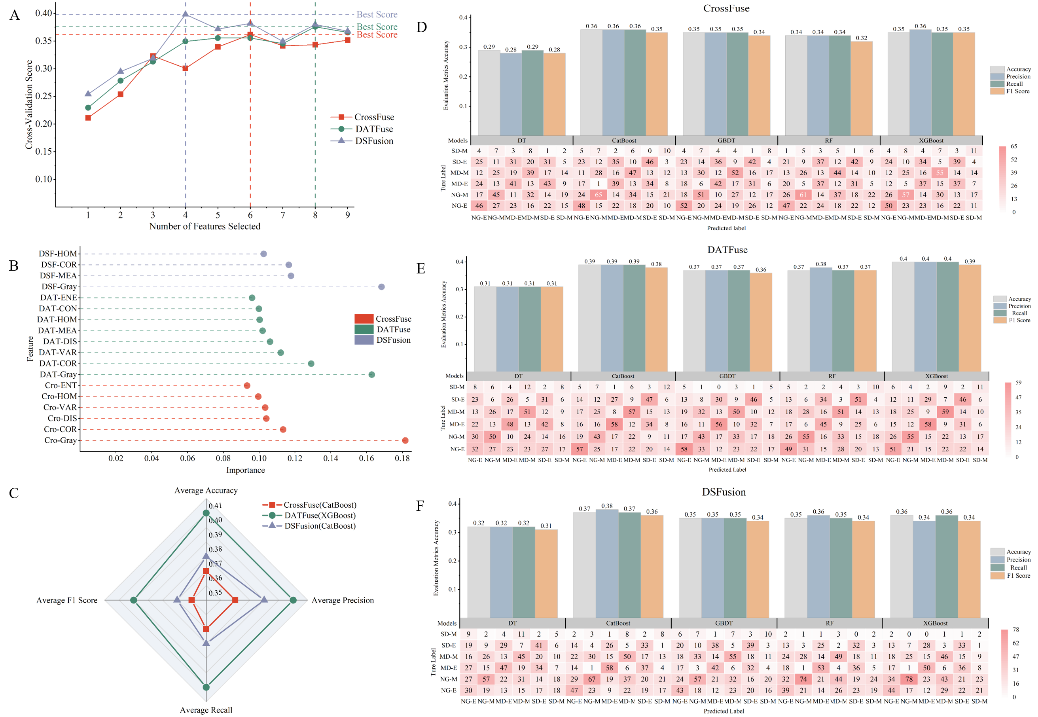 a. 灰度图像融合算法下特征筛选与机器学习模型结果
a. 灰度图像融合算法下特征筛选与机器学习模型结果
 b. RGB图像融合算法下特征筛选与机器学习模型结果
b. RGB图像融合算法下特征筛选与机器学习模型结果
3.特征层融合中常见特征组合对于杨树干旱监测的精度优于全特征组合
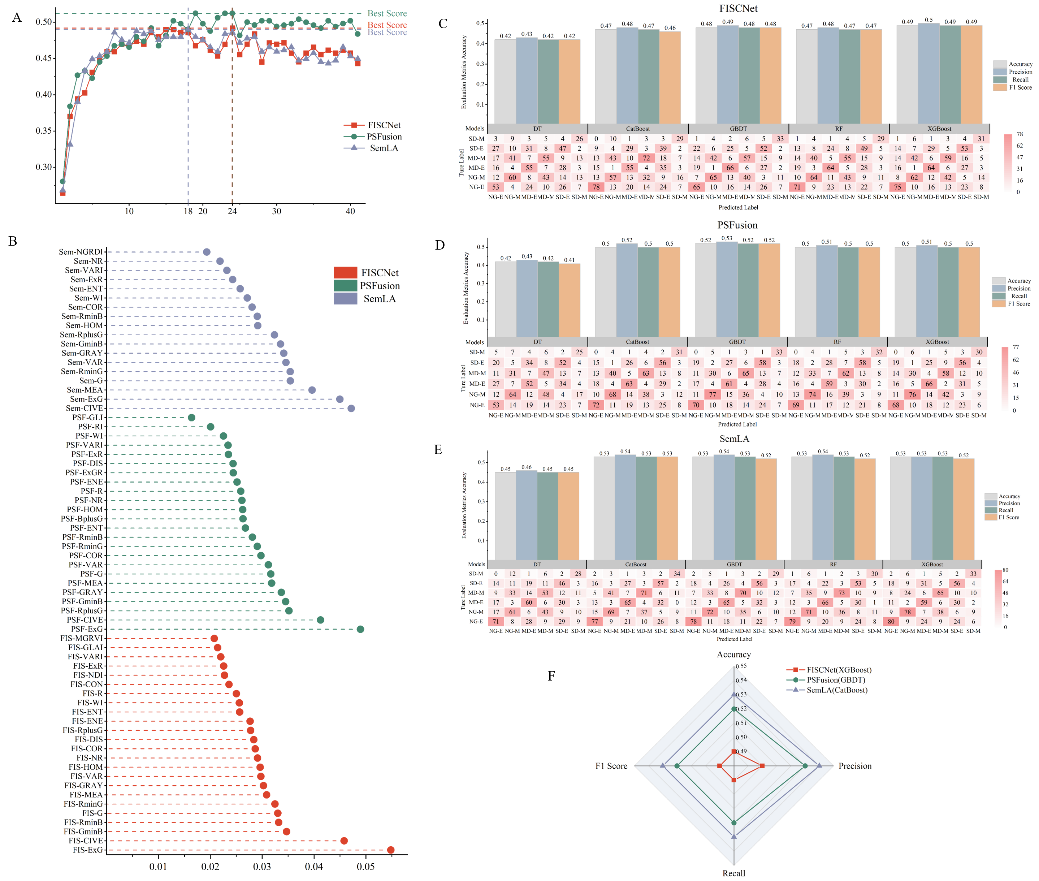
研究者基于热红外和可见光数据,研究分别提取温度特征、热红外纹理特征、植被指数及可见光纹理特征。为评估特征层融合在杨树干旱监测中的效果,研究设计了两组输入特征组合:常见特征组合(植被指数和温度特征)与全特征组合(植被指数、温度特征、可见光纹理特征和热红外纹理特征)。通过特征筛选和超参数优化,确定最优特征组合及参数配置,并采用RF、XGBoost、GBDT、DT和CatBoost五种算法构建干旱监测模型。结果显示,温度特征在两组最优特征组合中均占主导地位,其中最小温度特征(MinTc)重要性排名第一,凸显其在干旱监测中的高敏感性(图3a-b)。尽管常见特征组合的敏感特征数量较少,其模型性能优于全特征组合(图3c)。这表明,常见特征组合以更少的特征实现更高的精度和稳定性。总体而言,常见特征组合在杨树干旱监测中表现更优,凸显了温度特征和植被指数的核心作用。
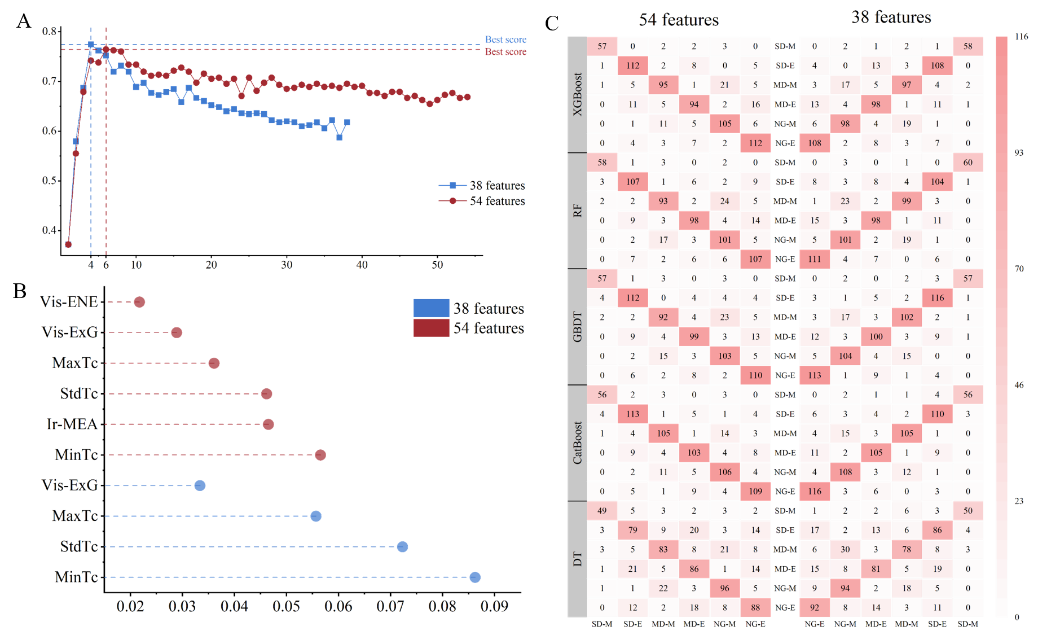 图3 特征层融合下特征筛选与机器学习模型结果
图3 特征层融合下特征筛选与机器学习模型结果
4.决策层融合下Stacking融合策略建立的杨树干旱监测模型精度高于Voting融合策略
研究人员采用软投票的Voting和基于逻辑回归的Stacking两种策略,基于热红外(提取温度和纹理特征)和可见光(提取植被指数和纹理特征)数据构建杨树干旱监测模型。通过特征筛选和超参数优化,结合RF、XGBoost、GBDT、DT和CatBoost算法,分别建立热红外和可见光基础模型,并选取最优模型进行决策层融合。结果显示,热红外特征数量较少但交叉验证分数更高,表明其对干旱敏感性更强(图4a-b)。基础模型中,CatBoost和GBDT在热红外模型中准确性最高,GBDT在可见光模型中表现最佳(图4c-d)。决策层融合中,以CatBoost(热红外)和GBDT(可见光)为基础,Stacking策略的模型在准确率、精确率、召回率和F1评分上优于Voting策略。总体而言,Stacking融合策略展现出更强的适应性,能有效整合热红外和可见光模型预测结果,显著提升杨树干旱监测性能。
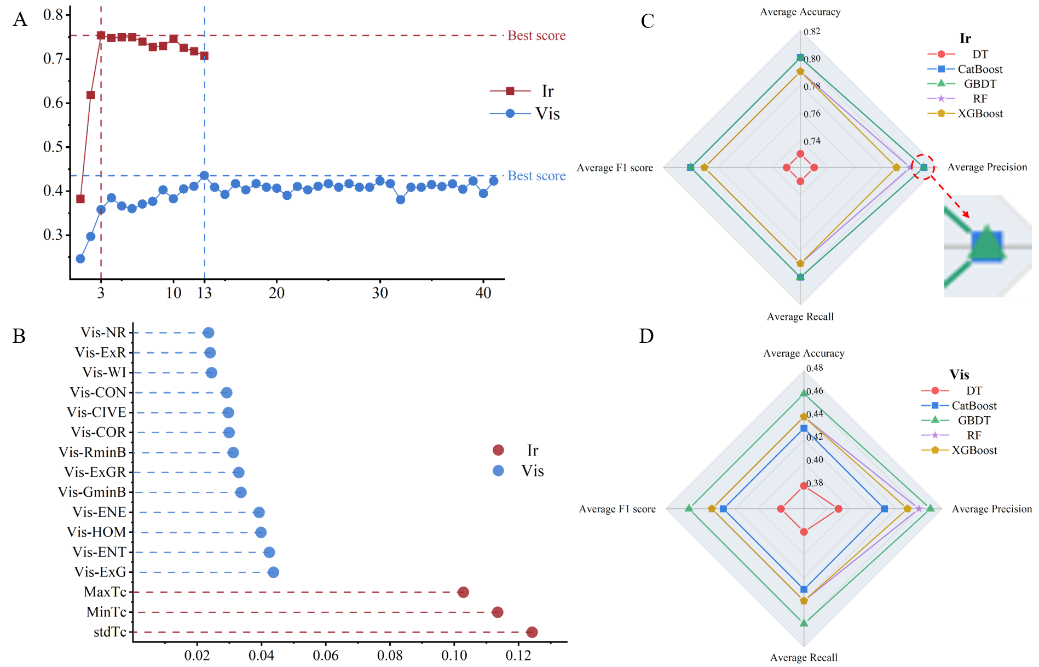 图4 决策融合基础模型特征筛选与机器学习模型结果
图4 决策融合基础模型特征筛选与机器学习模型结果
5.特征层融合对杨树干旱监测的效果最好且新表型特征无法作为原始特征的有效补充提升杨树干旱监测精度
研究人员比较了数据分解、数据层融合、特征层融合和决策层融合四种数据处理方法在杨树干旱监测中的效果。结果表明,特征层融合性能最佳,模型精度最高(图5)。特征层融合和决策层融合直接利用热红外和可见光图像的表型特征(如温度和植被指数),而数据分解和数据层融合需从处理后图像提取新特征(如纹理或融合特征)。为验证新表型特征有效性,研究将数据分解及数据层融合(灰度DATFuse和RGB SemLA算法)生成的新特征与原始特征结合,通过特征筛选和超参数优化,采用RF、XGBoost、GBDT、DT和CatBoost算法构建模型。结果显示,数据分解和灰度数据层融合的新特征与特征层融合的特征选择结果一致,模型性能未提升;RGB数据层融合的最优特征组合包含新特征和温度特征,但精度低于特征层融合。总体来说,特征层融合以高效特征整合在杨树干旱监测中表现最佳,数据分解和数据层融合的新特征未提供额外信息。
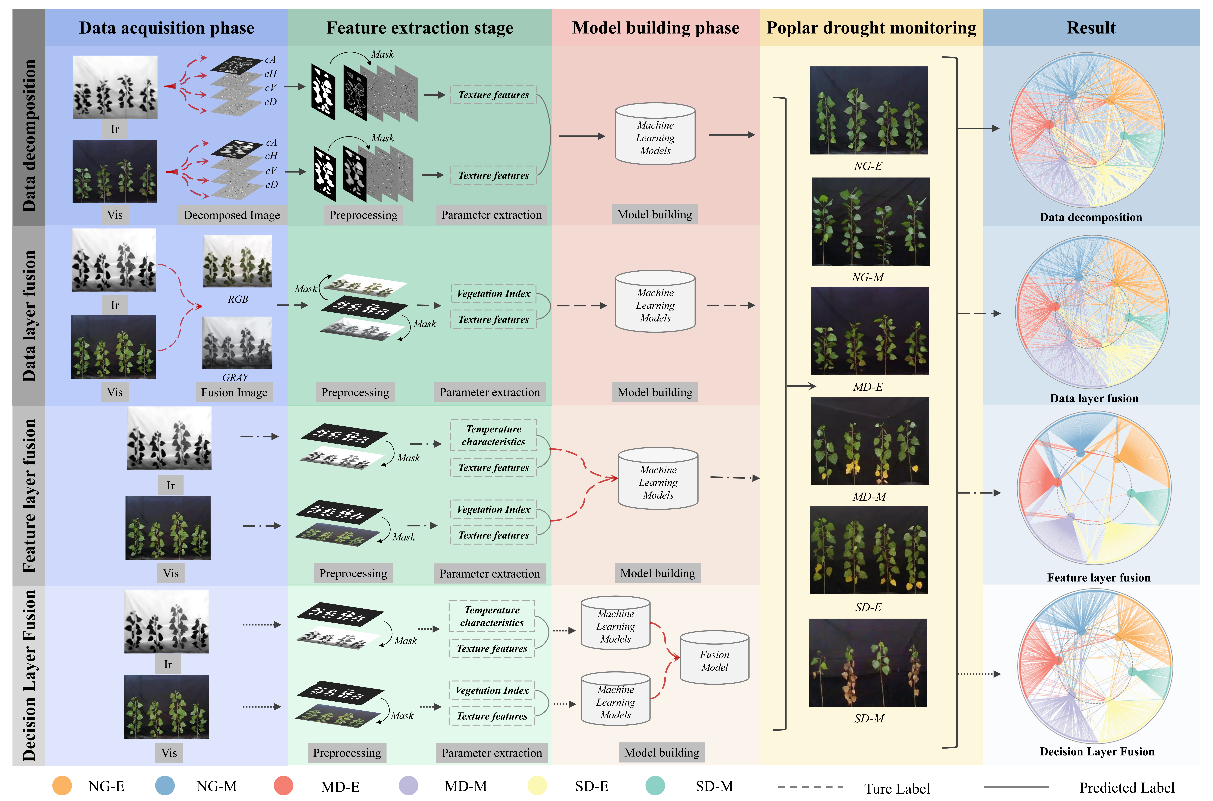 图5 不同数据处理方法图像处理过程及精度比较结果
图5 不同数据处理方法图像处理过程及精度比较结果
这项研究创新性采用数据“放大”(包括数据层融合、特征层融合和决策层融合)与“缩小”(数据分解)多种数据处理方法全面评估杨树干旱响应,突破传统单尺度分析局限,成功实现了对杨树干旱严重程度和持续时间的监测,构建了具有时空预测能力的林木干旱胁迫感知技术,为林木健康状况的动态跟踪与干旱响应的科学评估提供了理论基础和技术支持。
Zhou Ziyang, Zhang Huichun, Bian Liming, Zhou Lei, Ge Yufeng. Integrating sensor fusion with machine learning for comprehensive assessment of phenotypic traits and drought response in poplar species. Plant Biotechnology Journal. 2025,1-18
南京林业大学的教授团队和美国内布拉斯加大学林肯分校的葛玉峰教授团队和长期从事植物表型平台和技术研究,开展了植物生理、生化特性的高通量表型研究,致力于将工程技术引入表型分析,从而推动育种改良和精确农林的发展。
