学术中心
使用深度神经网络的分蘖估计方法
发布时间:
2022-05-19
来源:
本站
作者:
PhenoTrait
分蘖是禾本科植物植株上的分支,分蘖的数量是决定产量的最重要因素之一。传统上,分蘖数通常是通过手工计算的。然而破坏性调查给表型研究工作带来了瓶颈,因为它们费时费力,不可能跟踪植物的生长。因此,对于高通量表型来说,有必要采用自动化方法。传统的方法使用启发式特征来估计分蘖数。由于这些方法只使用了植物外观的一些启发式特征,它们没有充分利用图像中包含的信息。最近,使用深度神经网络(DNNs)学习的特征的图像识别技术的发展,超过了传统的手动特征提取方法的性能,直接从图像外观中学习图像特征。因此,DNNs学习的特征充分利用了植物的外观。这促使我们可以使用DNN来学习特征,作为实现高准确度分蘖数估计的手段。然而,由于DNNs通常需要大量的数据进行训练,因此很难将其应用于无法获得大量训练数据集的估计问题上。在本文中,我们使用两种策略来克服训练数据不足的问题:使用预训练的DNN模型和使用预先任务(pretext tasks)来学习特征。
我们利用得到的DNN提取特征,并通过回归模型估计分蘖数。分蘖数是通过回归来估计的,提取的特征被用作回归的独立值。方法使用的是两种回归模型:支持向量回归(SVR)和线性回归(LR)。预先任务是估计输入图像中植物的面积和长宽比。训练用的图像是没有标记的,只有分蘖数。图像中植物的面积和长宽比的基本事实是事先用图像处理计算出来的。通过更新参数来训练DNN模型,以减少DNN的输出和地面实况之间的误差。
我们使用六倍交叉验证法来计算分蘖数估计的准确性。也就是说,图像被分为六组,用五组训练回归模型,用剩下的一组进行验证。这个过程重复进行,直到所有组都被用于验证。模型的准确性是通过取六个交叉验证任务中每个任务的平均值来计算的。我们采用平均绝对误差(MAE)来评价所提方法的准确性。
图1和图2分别比较了使用SVR和LR进行分蘖数估计的情况,测量的分蘖数(横轴)和估计的分蘖数(纵轴)。图中,黑线表示测量和估计的分蘖数相同时,红点和蓝点表示样本。因此,点越接近黑线,估计结果就越准确。
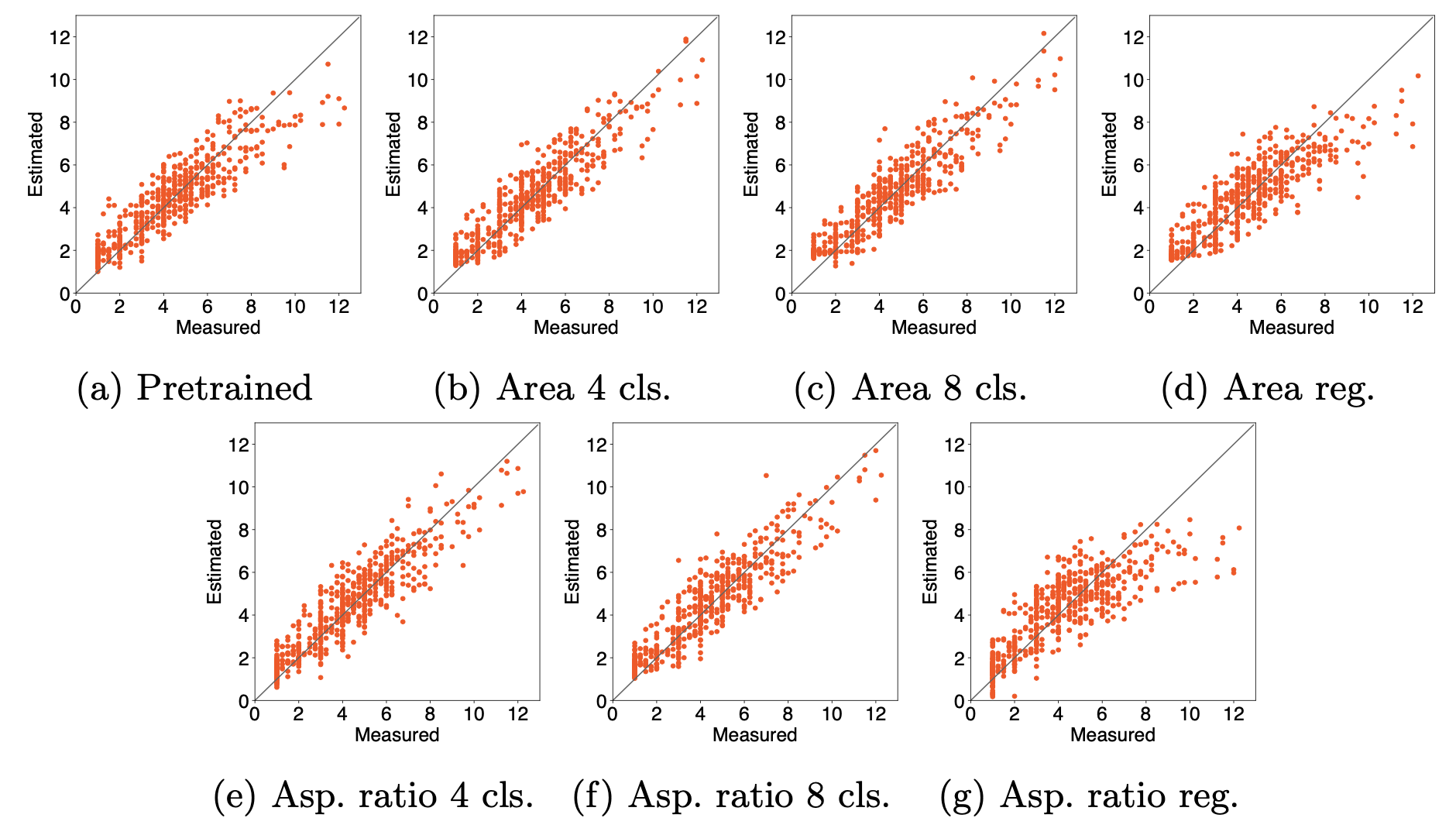
图1使用SVR进行分蘖数估计的实验结果。横轴和纵轴分别代表测量和估计的分蘖数。每个红点表示一个估计分蘖数的样本。黑线表示测量和估计数据匹配的情况。因此,点越接近黑线,估计就越准确。
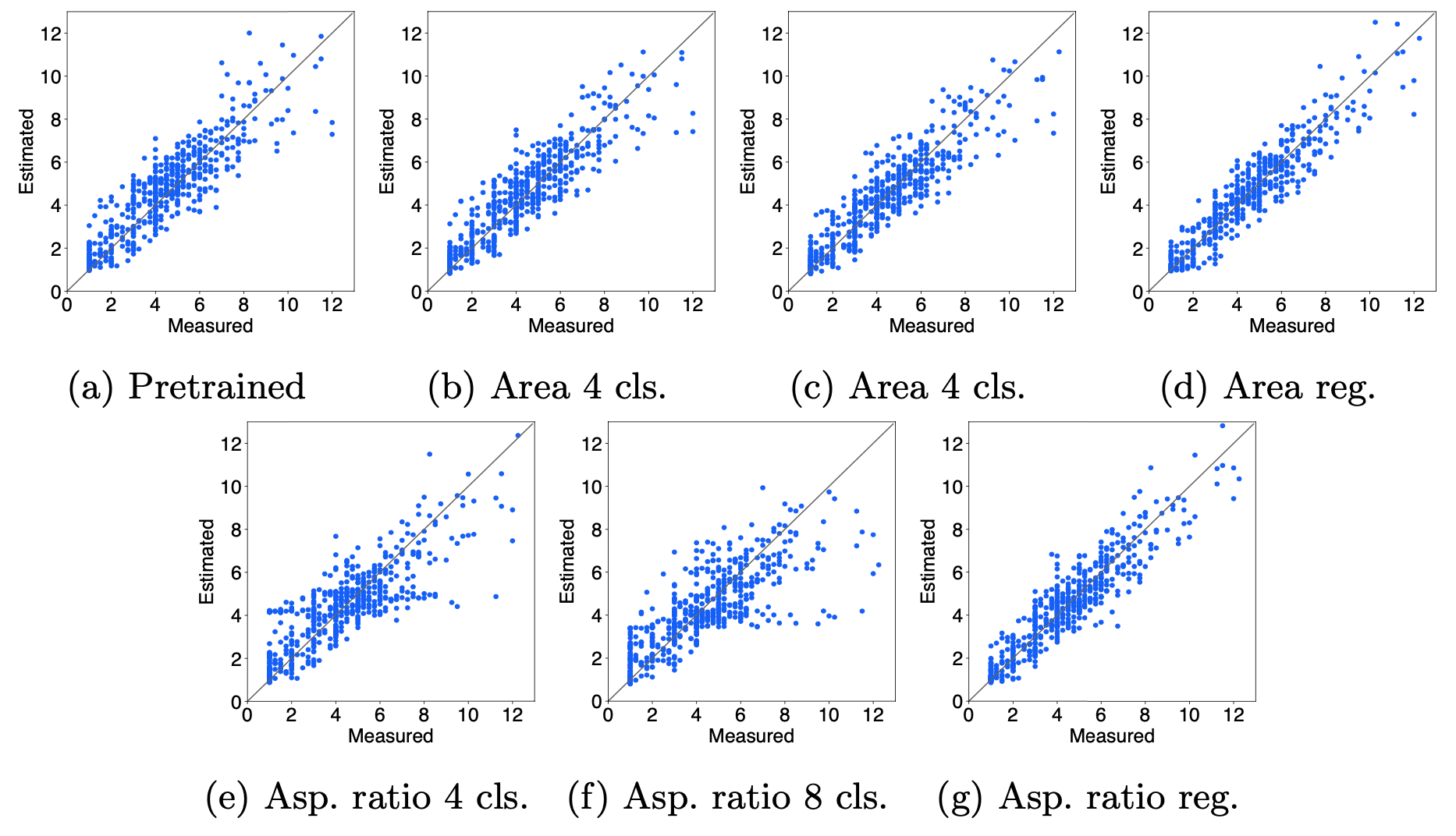
图2使用LR进行分蘖数估计的实验结果。
本文提出了一种基于DNN的分蘖估计方法,与传统方法相比,该方法取得了很好的性能。本文提出的方法使用两个独立的模型进行特征提取:一个预训练的VGG-16模型和一个通过解决预先任务产生的模型。我们同时考虑了SVR和LR来估计分蘖数。实验结果表明,预训练的模型和基于借口任务的模型使所提方法的性能优于传统方法。
来源:Kinose, R., Utsumi, Y., Iwamura, M., & Kise, K. (2022). Tiller estimation method using deep neural networks.
编辑:婷婷
推荐新闻

视频展示
联系我们
慧诺瑞德(北京)科技有限公司
地址:北京市海淀区西三旗街道建材城中路12号院8号楼2门
电话:010-62925490、82928854、82928864、82928874、18600875228
传真:010-62925490-802
Email: info@phenotrait.com
邮编:100096
在线留言
关注我们
植物表型圈
植物表型资讯