学术中心
面向农业深度学习模型高效训练的数据集标准化和集中化
发布时间:
2023-09-14
来源:
本站
作者:
PhenoTrait
近年来,深度学习模型已成为农业计算机视觉的标准。这种模型通常使用模型权重对农业任务进行微调,最初适用于更通用的非农业数据集,缺乏针对农业的微调可能会增加培训时间和资源使用,并降低模型性能,导致数据效率整体下降。为了克服这一限制,我们为三个不同的任务收集了广泛的现有公共数据集,并将其标准化,同时构建了标准的训练和评估管道,为我们提供了一组基准和预训练模型。然后,我们使用深度学习任务中常用的方法进行了大量实验,但在农业的特定领域应用中尚未探索。我们的实验指导我们在训练农业深度学习模型时开发了许多方法来提高数据效率,而无需对现有管道进行大规模修改。实验结果表明,即使是轻微的训练修改,如使用农业预训练模型权重或在数据处理管道中采用特定的空间增强,都可以显著提高模型性能,并实现更短的收敛时间内节省训练资源。此外,我们发现,即使是在低质量注释上训练的模型也可以产生与高质量等价的性能水平,这表明具有低注释的数据集仍然可以用于训练,扩大了当前可用的数据集池。所提出方法广泛适用于整个农业深度学习,具有显著提高数据效率的巨大潜力。
在我们的工作中,我们开发了一组新的标准化和集中式农业数据集以及使用最先进模型的基准和预训练模型。我们的定制管道在不使用大量数据或架构修改的情况下实现了与现有基准相当的性能,使其广泛适用于各种农业深度学习任务。我们还评估了许多现有的方法,用于改进农业领域特定的模型性能,包括使用农业预训练的模型权重和图像增强。此外,我们甚至探索了传统上被忽视的低质量数据的可行性,潜在地扩大农业数据库。实验结果表明,轻微的训练修改可以显著提高模型性能,并缩短收敛时间。我们已经开放了我们工作中使用的数据集的标准化和集中化版本以及我们的预训练模型和基准,以指导更便利地采用我们描述的方法。

图1 来自COCO数据集(第1行)和各种农业数据集中(第2行)的图像样本,展示了COCO图像的一般环境和农业图像的特定环境之间的对比。(注:这些图像以其原始纵横比显示)
 表1 作为本研究的一部分使用的公开可用农业数据集的列表(如数据集名称所述)以及它们的图像数量、农业任务和上述模型在测试集(基准测试)上的相应基准性能
表1 作为本研究的一部分使用的公开可用农业数据集的列表(如数据集名称所述)以及它们的图像数量、农业任务和上述模型在测试集(基准测试)上的相应基准性能
 图2 本研究中使用的语义分割数据集的样本图像(包含带有注释分割掩码的原始图像,这些图像以其原始纵横比显示)
图2 本研究中使用的语义分割数据集的样本图像(包含带有注释分割掩码的原始图像,这些图像以其原始纵横比显示)
 图3 本研究中使用的物体检测数据集的样本图像,包含带有注释水果边界框的原始图像(每个图像来源的数据集都会在其顶部进行注释,这些图像以其原始纵横比显示)
图3 本研究中使用的物体检测数据集的样本图像,包含带有注释水果边界框的原始图像(每个图像来源的数据集都会在其顶部进行注释,这些图像以其原始纵横比显示)
 表2 每项任务的核心训练参数汇
表2 每项任务的核心训练参数汇
 表3 单类检测的预训练模型方法概述
表3 单类检测的预训练模型方法概述
 表4 用于语义分割的预训练骨干的摘要
表4 用于语义分割的预训练骨干的摘要
 图4 加利福尼亚葡萄检测的一个示例图像
图4 加利福尼亚葡萄检测的一个示例图像
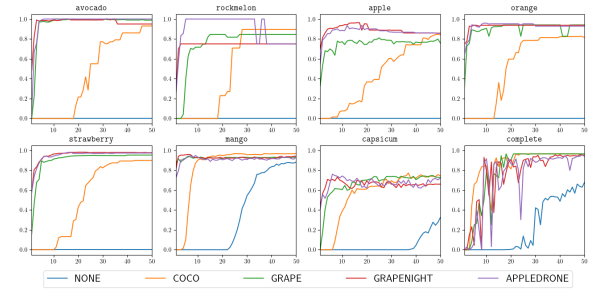 图5 mAP@0.5来自全球水果检测数据集的七种不同水果的值以及完整的数据集
图5 mAP@0.5来自全球水果检测数据集的七种不同水果的值以及完整的数据集
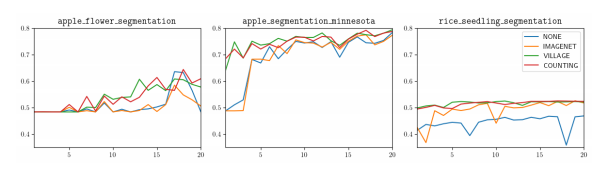 图6 在三个不同的评估数据集上,四个不同的预训练骨干的mIOU值的比较
图6 在三个不同的评估数据集上,四个不同的预训练骨干的mIOU值的比较
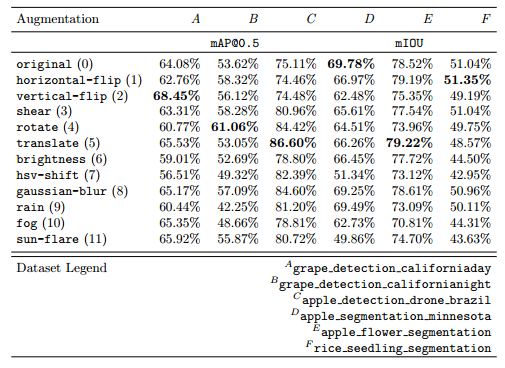 表5 不同增强在上述语义分割和对象检测数据集上的性能摘要(粗体表示某个数据集的最高性能)
表5 不同增强在上述语义分割和对象检测数据集上的性能摘要(粗体表示某个数据集的最高性能)
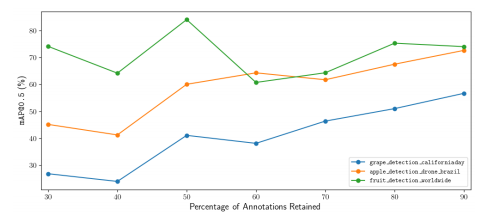 图7 模型在三个不同数据集上的性能取决于每张图像保留的边界框注释的百分比
图7 模型在三个不同数据集上的性能取决于每张图像保留的边界框注释的百分比
 图8 在不同级别的注释质量上训练的模型的样本预测
图8 在不同级别的注释质量上训练的模型的样本预测
 图9 通过其相应的基准模型对全球水果检测数据集进行的地面实况和预测注释示例
图9 通过其相应的基准模型对全球水果检测数据集进行的地面实况和预测注释示例
Amogh J, Mason E, Dario G. 2023. Standardizing and Centralizing Datasets for Efficient Training of Agricultural Deep Learning Models. Plant Phenomics
编辑
陈秀娇
推荐新闻

视频展示
联系我们
慧诺瑞德(北京)科技有限公司
地址:北京市海淀区西三旗街道建材城中路12号院8号楼2门
电话:010-62925490、82928854、82928864、82928874、18600875228
传真:010-62925490-802
Email: info@phenotrait.com
邮编:100096
在线留言
关注我们
植物表型圈
植物表型资讯